Decomposing domain models based on lifecycles
Good decomposition is one of the most important parts of software design. Unfortunately it’s also one of the hardest. We all know that modular design is a good thing. But how do we make our systems more modular?
There’s no easy or right answer here. What we can do instead is to gather a nice set of heuristics that allows you to try different decomposition patterns and see what works.
Let’s see one of the possible ways of decomposing your domain model.
Our problem domain
Let’s look at the following model from the system in the logistics domain.
The business flow is as follows:
- As a client, you can schedule a shipment of goods.
- Drivers can bid for that shipment. Bidding is finished when the client accepts the best offer.
- After the bidding, the client has to pay the price, the driver is notified and can proceed to pick up the shipment
- Once the shipment is delivered the driver receives a payment
Anemic model
A common modelling practice is to follow the nouns in your domain and start with the database schema first:
defmodule Shipment do
use Ecto.Schema
schema "shipments" do
# one of: bidding, pending_payment, in_progress, completed, canceled
field :state, :string
field :pickup_location, Geo.Point
field :destination_location, Geo.Point
field :pickup_time, :utc_datetime
field :delivered_at, :utc_datetime
field :package_description, :string
field :maximum_price_in_cents, :integer
field :bidding_ends_at, :utc_datetime
field :winning_bid_id, :integer
belongs_to :client, User
belongs_to :driver, User
has_many :bids, Shipment.Bid
timestamps()
end
end
defmodule Shipment.Bid do
use Ecto.Schema
schema "bids" do
field :driver_id, :integer
field :price_in_cents, :integer
belongs_to :shipment, Shipment
timestamps()
end
end
This approach results in the anemic domain model.
Instead of expressive, easy to change domain code, most of the application logic
is handled by the create and update operations on a few big schemas, modifying
a subset of the fields:
defmodule Shipments do
def create_shipment(client_id, params) do
%Shipment{state: :bidding, client_id: client_id}
|> Shipment.create_changeset(params)
|> Repo.insert()
end
def bid(shipment_id, driver_id, price_in_cents) do
shipment = get_shipment(shipment_id)
if price_in_cents <= max_price_in_cents do
%Bid{}
|> Bid.create_changeset(%{
shipment_id: shipment_id,
driver_id: deriver_id,
price_in_cents: price_in_cents
})
|> Repo.insert()
else
{:error, :price_too_high}
end
end
def select_bid(shipment_id, bid_id) do
shipment = get_shipment(shipment_id)
bid = get_bid(bid_id)
shipment
|> Shipment.bid_changeset(%{winning_bid_id: bid_id, state: "pending_payment"})
|> Repo.update()
notify_driver(shipment_id, bid.driver_id)
end
# ...
end
Some of the problems with this approach:
- Unit testing is hard. If we want to properly test the functionality we have to rely on big setup blocks (especially for tests in the final steps in the flow)
- Code is not expressive. The domain model and business rules are implicit instead of being visible in the code. This makes the system hard to change because it’s easy to violate business rules and invariants by mistake.
- The
Shipmentschema is already huge and it’s only going to grow as new features are added. - Adding new states in the middle of the business flow is hard - so is rearranging and modifying the existing flow.
- A lot of defensive programming is necessary to prevent incorrect states.
Decompose by lifecycle
Let’s try to visualise the flow of a shipment:
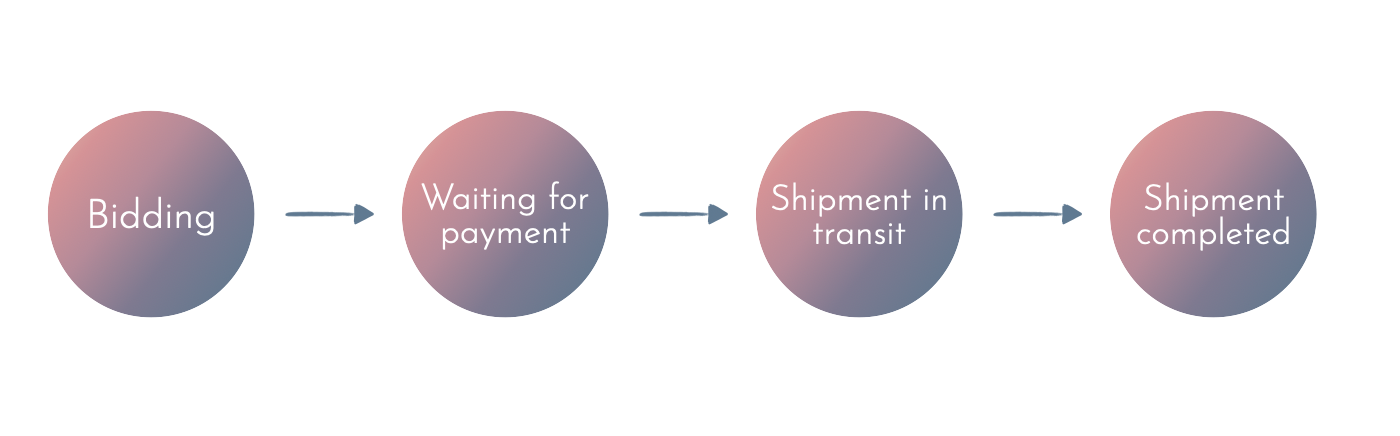
Then, we can try to come up with a module for each step:
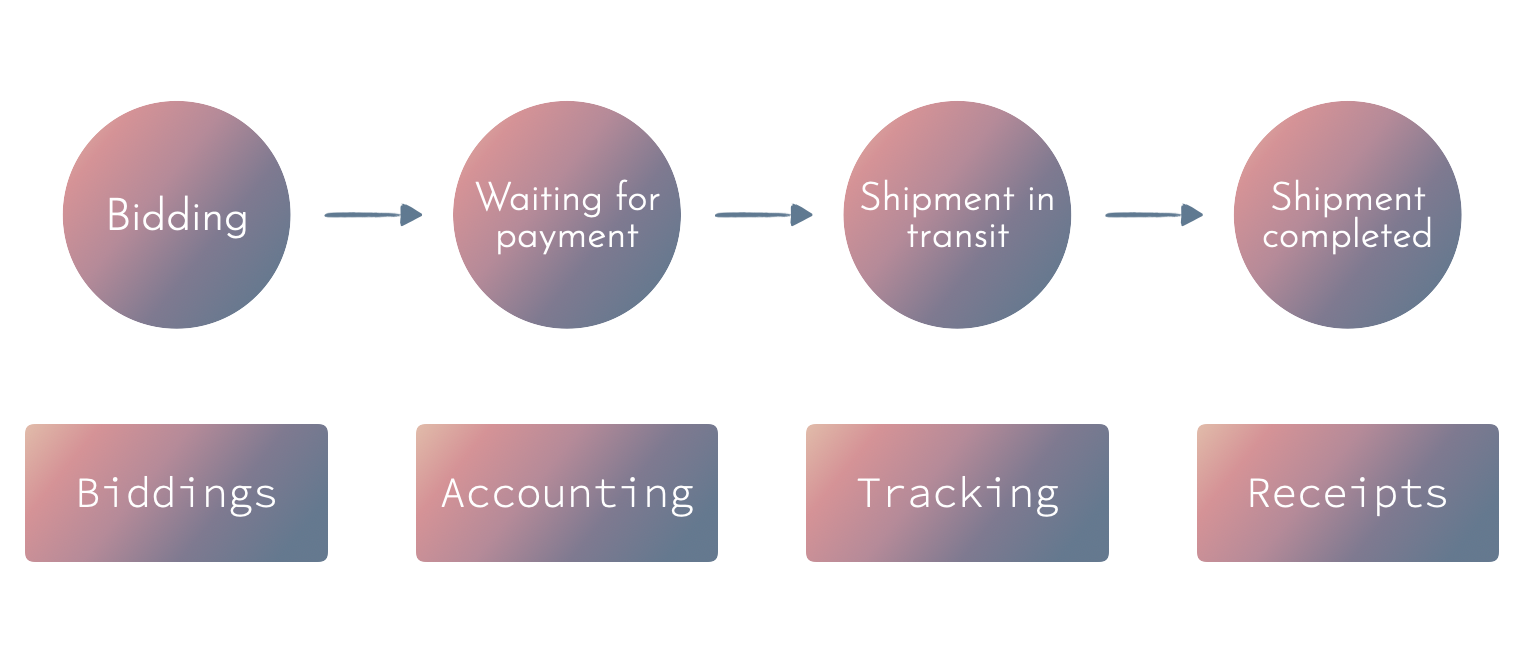
Then, we can model each piece in isolation.
defmodule Biddings.Bidding do
use Ecto.Schema
schema "biddings" do
field :client_id, :integer
field :shipping_id, :integer
field :end_time, :utc_datetime
field :maximum_price_cents, :integer
timestamps
end
# ...
end
defmodule Biddings.Bid do
use Ecto.Schema
schema "bids" do
field :shipping_id, :integer
field :driver_id, :integer
field :price_cents, :integer
end
# ...
end
defmodule Biddings do
# ...
def start(shipment_id, end_time, maximum_price_in_cents) do
%Bidding{}
|> Bidding.changeset(%{
shipment_id: shipment_id,
end_time: end_time,
maximum_price_cents: maximum_price_cents
})
|> Repo.insert!()
:ok
end
def fetch_winning_bid(shipment_id) do
Bid
|> where(shipment_id: ^shipment_id)
|> order_by(asc: :price_in_cents)
|> limit(1)
|> Repo.one()
end
def bid(shipment_id, driver_id, price_in_cents) do
case validate_bid(shipment_id, price_in_cents) do
:ok -> save_bid(shipment_id, driver_id, price_in_cents)
{:erorr, :no_bidding} -> {:error, :no_bidding}
{:error, :bid_too_high} -> {:error, :bid_to_high}
end
end
def end_bidding(shipment_id) do
with :ok <- verify_active_bidding(shipment_id),
{:ok, bid} <- fetch_winning_bid(shipment_id) do
:ok = notify_driver(shipment_id, bid.driver_id)
:ok = archive_bidding(shipment_id)
else
{:error, :bidding_ended} -> {:error, :bidding_ended}
{:error, :no_bids_placed} -> {:error, :no_bids_placed}
end
end
defp archive_bidding(shipment_id) do
# delete it, soft-delete, or store in some other way, depending on
# functional and non-functional requirements
end
# ...
end
Tying it all together
Now we have the flow split into several different isolated pieces. To make it work, we have to tie it all together. We have at least two approaches:
- Application/Service Layer approach
- Event-driven / PubSub approach
(Both have their use cases and trade-offs, so I won’t compare them in this article)
Application Layer approach
In the Application Layer approach, you have two layers: domain layer and application layer. The domain layer consists of the isolated modules we already discussed. The application layer is responsible for tying the domain models into a full business flow.
defmodule ShippingService do
# ...
def select_driver(client_id, shipment_id, driver_id) do
# You can use a DB transaction here to ensure data consistency
with :ok <- authorize(client_id, shipment_id),
:ok <- Bidding.end_bidding(shipment_id),
%Bid{} = bid <- Bidding.fetch_winning_bid(shipment_id),
:ok <- Accounting.request_payment(client_id, shipment_id, bid.price_in_cents) do
:ok
end
end
# ...
end
Event-driven / PubSub approach
With an event-driven approach, you don’t have a separate layer that connects the domain modules. Instead, you use a PubSub mechanism (synchronous or asynchronous) to pass events between the modules.
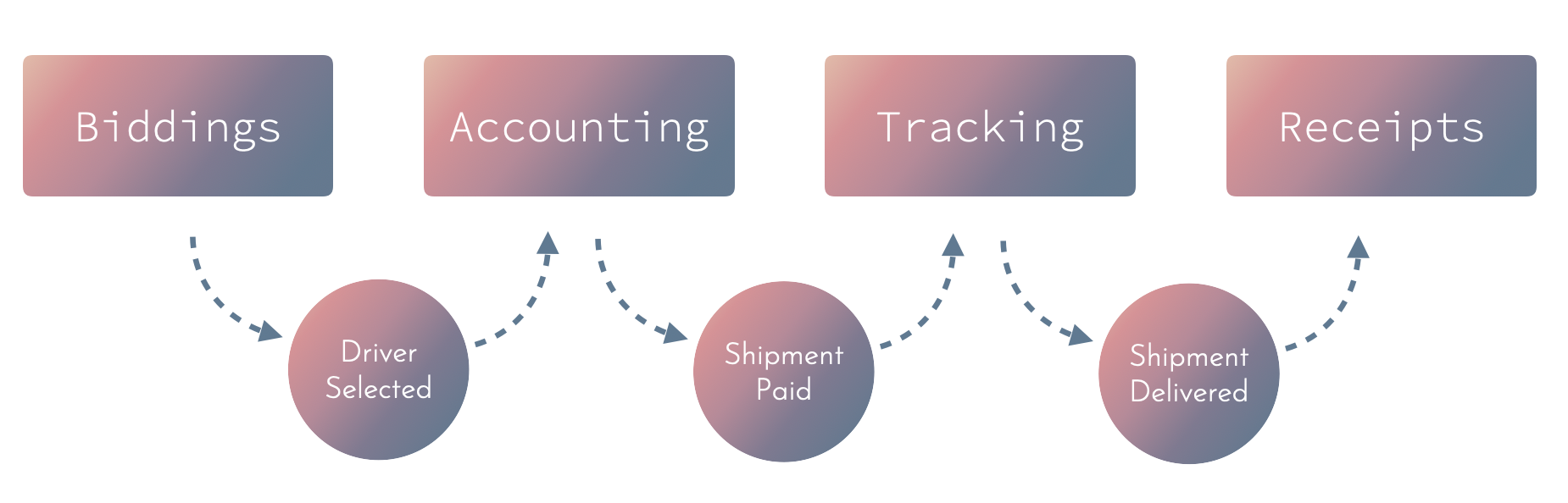
Tips for decomposing
- The
statefield in the anemic model corresponds closely to the new decomposition. Every time I see astatefield on some model, I wonder whether it should be split into separate models. - Look for times when the system switches the actor it interacts with. In our example, sometimes the system interacts with the client, sometimes it waits for the drivers. Look for different user types, different roles in the organisation, external systems etc, interacting with the same domain model.
- Another way is to look at the fields in your database schemas. Fields which
can be
nullare a good thing to look at. Finding when those fields change from null to not null is a good candidate for decomposition.
Costs and benefits
Please take a look at my other articles:
That’s it!
What I described is just one technique for software decomposition. While it won’t fit all needs and won’t solve more problems, I hope it gives you one more tool you can use to make your system more modular.
Since there’s a lot more to say about this topic, I’m looking forward to writing more about it in the future. If you want to read about it more, please follow me on Twitter (@mkaszubowski94) or sign up to the newsletter below.
I’d love to hear your thoughts and comments. Please respond to this tweet if you’d like to talk!