Handling failures in Elixir and Phoenix
Fault tolerance is one of the most often mentioned reasons for using Elixir. And this is true — being fault tolerant was probably the most important driving force behind Erlang.
During the years, a lot of amazing stuff has been already written on dealing with failures in Erlang (Elixir) and OTP. Yet, in my opinion, most of the resources describe fairly advanced language features and are not really helpful for beginners.
So, in this article, I’ll try to tackle only one problem — handling errors and failures in web applications using Phoenix Framework (it’s still true for other frameworks and libraries like Plug or cowboy).
Handling a HTTP request
Disclaimer: The following description of the way web servers work is highly simplified and may not reflect the current state of the ecosystem (or I could just be wrong). The point, however, is not to claim that other technologies are doing something wrong (or that they are worse)— the point is to emphasise the benefits of Erlang/Elixir way of solving this problem. If you can correct me in the comment box, please do!
Traditionally, almost all web servers followed the same pattern when it comes to handling a HTTP request. In what is basically a big loop, the server waits for the request to arrive, does some stuff depending on the request type, sends a reply and goes back to the beginning of the loop. Of course, to make things faster, we can use multiple threads/processes for handling the requests concurrently (or in parallel).
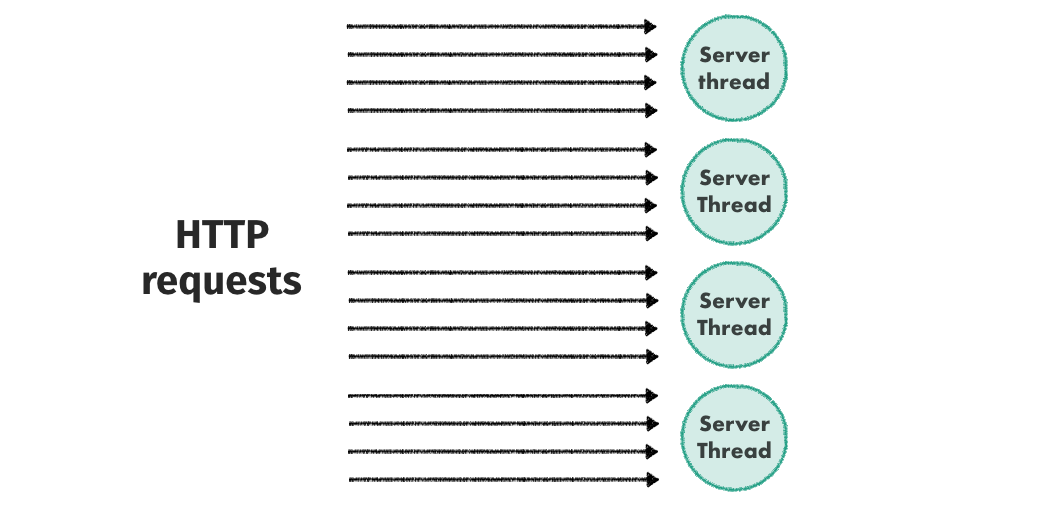
Server running in such a loops means that the request are handled synchronously. When one of them is handled, all the others are waiting for their turn (one counter example might be Node.js, but the failure semantics are mostly the same).
Of course no software is free of bugs and a thread can fail from time to time. The reason can be a memory leak, a database connection timing out or some other unhandled exception. When this happens, all the request that were waiting to be handled also fail. Not only does it impact the user experience, it can also impact the application performance.

Blocking
In addition to failures, this model has one more disadvantage. We’ve already learned that requests are handled synchronously within a thread. Now, let’s imagine that one particular request takes a long time. It might be doing some heavy computation, be blocked on I/O (database, disk, network) or be stopped by the garbage collector.
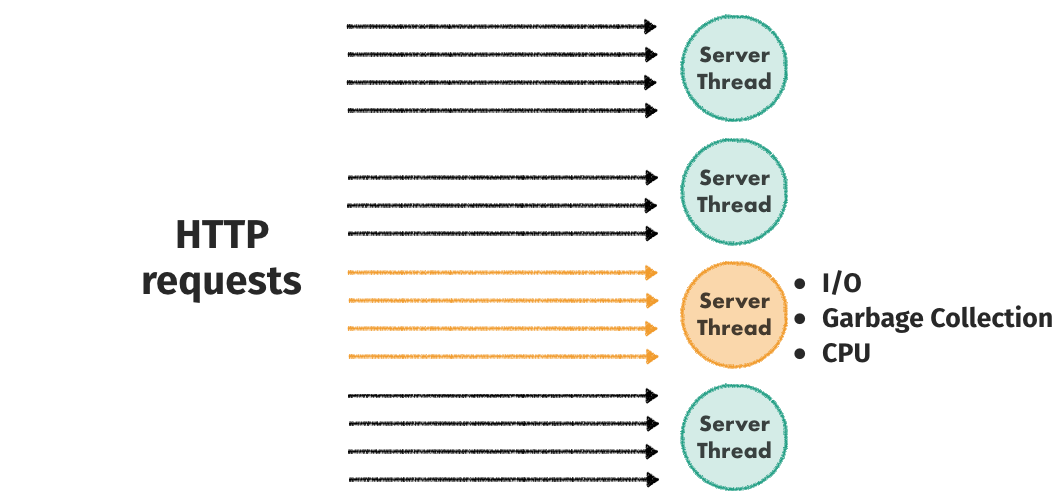
In a typical web server, such a request will block all the requests behind them even if it’s not doing anything important itself. This is just like being blocked in the line at the post office by someone who has fallen asleep. Doesn’t make sense, does it?
(To make things even worse, some languages can even stop all the threads while doing garbage collection)
The Elixir way
Thanks to the BEAM (Erlang Virtual Machine), we have a really powerful tool at our disposal: lightweight processes. Instead of handling multiple HTTP requests synchronously, we can spin off an independent process for each of them. Such process would handle the request, send a response and then terminate gracefully. That’s exactly what the Phoenix Framework does.

Because each process is independent, their failures don’t affect each other and neither do garbage collection or I/O pauses.
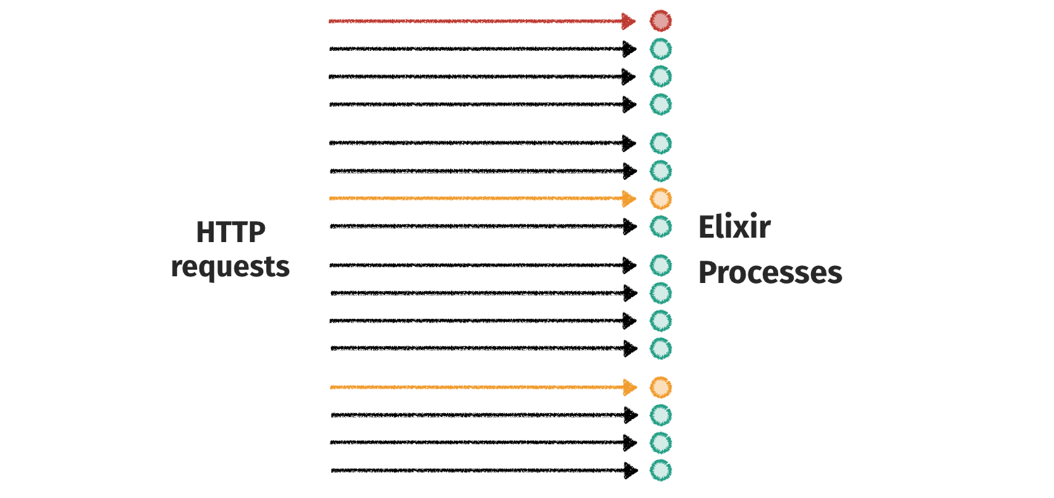
There are multiple advantages here.
The most obvious is the failure isolation — when one request makes something wrong and causes the process to crash, the crash isn’t propagated to any other part of the system. This is great for ensuring that the server cannot be brought down by some invalid requests repeated over and over again. The same goes for all the blocking operations.
The process can take as long (and/or use as much CPU) as it needs without impacting the throughput of the system — the scheduler inside the Virtual Machine will just pause such a process for a while and restore it after some short time just like Operating Systems does (it’s called preemptive scheduling). By using completely isolated processes to handle each request we also gain the benefit of great parallelism which is great for the performance.
But there’s one more, equally important benefit.
Coding only for the happy path
Apart from benefits in the runtime, allowing requests to fail gives us another huge advantage in the code — you can write less code because you only code for the happy path and doesn’t have to care about unexpected errors. You just let one process fail and can be sure that this will have no impact on the rest of the system.
Unfortunately, a lot of us still default to writing code like this:
def add_contact(current_user_id, nil), do: {:error, :invalid_contact_id}
def add_contact(current_user_id, ""), do: {:error, :invalid_contact_id}
def add_contact(current_user_id, contact_id) do
params = %{user_id: current_user_id, contact_id: contact_id}
%Contact{}
|> Contact.Changeset(params)
|> Repo.insert()
|> case do
{:ok, contact} -> {:ok, contact}
{:error, changeset} -> {:error, changeset}
end
end
Seems fine, doesn’t it? But let’s look closely:
def add_contact(current_user_id, nil), do: {:error, :invalid_contact_id}
def add_contact(current_user_id, ""), do: {:error, :invalid_contact_id}
This code itself isn’t bad. When we receive anil or an empty string instead of
a valid user_id, it makes sense. But let’s take a step back: what needs to
happen to receive such value here?
One option is that an end-user has forgotten to pass the value — it’s possible when we create a public API — and we should probably render a valid response. (But still, I’ll argue that this basic validation should be done directly in the controller, not in the function doing the real work).
The other option is: someone has made a mistake. It might have been a developer using this function, it might have been a developer responsible for making the API call from a mobile application or a web page. In this case, handling such a thing is not a good idea. Before explaining why, let’s look at another fragment:
|> Repo.insert()
|> case do
{:ok, contact} -> {:ok, contact}
{:error, changeset} -> {:error, changeset}
end
This is one of the most popular patterns I see in the code. It’s so common, that
we don’t even think when wrapping each Repo.insert/Repo.update in
a case statement. This is a huge mistake.
Params passed to the changeset are: %{user_id: current_user_id, contact_id:
contact_id}. So, what is the possible reason for the error here? If you think
for a moment, it’s quite clear that this pair should be unique. So, the only
reasonable error is caused by violating the unique index constraint. Again,
let’s take a step back. Why would it happen? The most probable reason is a
duplicated request to add a contact. So, maybe there’s no point in returning the
error? In this case, the most reasonable response for the error is to return a
successful response with the existing contact:
def add_contact(current_user_id, contact_id) do
params = %{user_id: current_user_id, contact_id: contact_id}
%Contact{}
|> Contact.Changeset(params)
|> Repo.insert()
|> case do
{:ok, contact} ->
{:ok, contact}
{:error, %{errors: [contact_id: "is already taken"]} ->
contact = Repo.get_by(Contact, user_id: current_user_id, contact_id: contact_id)
{:ok, contact}
end
end
See? By thinking about what wrong can happen and what errors are possible we were not only able to eliminate unnecessary code, but also improved the behaviour to better match the expectations.
Conclusion
Elixir and BEAM give as a great tool to reduce the amount of error handling code we have in our applications. Let’s use it. Instead of trying to handle every possible error blindly, try to understand possible scenarios and, only then, decide which of them are worth handling in a nice, user-friendly way. Don’t try to handle errors when you don’t know how to deal with them. This will not only make your code shorter, but also easier to debug and maintain.
I guess the key insight here is: you, as a developer, shouldn’t try to handle your own errors in a nice way. You should make sure it fails loud and fast so you are able to fix it before it’s released. This is exactly what the “Let it crash!” philosophy is about — if you know how to handle the error, go for it. If you don’t, just let the process crash and be sure that your system can survive that.